De matemáticos y charlatanes: por qué es imposible predecir qué va a pasar dentro de unos días con la covid-19

Poco después del inicio de la pandemia de la covid-19, nos tocó comenzar a sufrir otra epidemia: la de matemáticos, físicos, ingenieros e incluso algún químico despistado que surgieron de bajo las piedras con predicciones más o menos acertadas de la evolución de nuevos casos de infectados, fallecidos, hospitalizados y lo que se quiera imaginar. Los medios de comunicación se llenaron de chicos de la curva y otros fantasmas vendiendo esperanza o terror, según tocase, disfrazados de sesudas matemáticas y estadística. Algunos de estos profetas son académicos serios que han querido aportar su granito de arena con la mejor de las intenciones; otros son charlatanes que se aprovechan del anumerismo rampante (ese que parece que el Ministerio quiere consolidar dándole una buena colleja a las matemáticas del bachillerato) para deslumbrar al personal con predicciones de una precisión apabullante que, si se miran con un poco de cuidado, son siempre a toro pasado. ¿Cómo puede un ciudadano medio, de los que se sonrojan si se les pide que hagan una regla de tres, distinguir entre profesionales de la modelización y vendedores de humo? Tenemos dos noticias para ese ciudadano, una buena y una mala. La buena es que no hace falta que los distinga. El motivo es la mala noticia: en fenómenos como epidemias, es imposible realizar una predicción precisa de lo que va a ocurrir a poco más de unos días vista. Repetimos: a cualquiera que intente decirnos el número de muertos que va a haber un día cualquiera con una antelación de una semana o más, ni caso.
¿Y por qué incluso académicos intachables están cayendo en la tentación de decir a las administraciones lo que deberían hacer basándose en modelos matemáticos? En 1927 se publicó el modelo SIR, piedra angular de la epidemiología moderna. El modelo divide una población en Susceptibles de contagiarse, Infectados, y en Retirados de la dinámica epidémica, que es un cajón de sastre en el que van juntos Recuperados y Difuntos porque, si la infección produce inmunidad como parece que es el caso con COVID-19, ni unos ni otros van ya ni a infectar a nadie ni a contagiarse de nuevo. Nuestras variables son el número de personas en cada una de estas categorías, y tendremos unas ecuaciones o reglas que nos dirán cómo evolucionan estos números. Estas ecuaciones son tan sencillas que cualquiera puede hacer su versión en casa y producir sus propias curvas en cuestión de minutos. Con un poco más de maña, se pueden meter categorías nuevas en el modelo, tunearlo para las características de la epidemia en nuestra región favorita, ajustar los parámetros del modelo para que reproduzcan mejor o peor la curva de datos hasta el día de hoy y, ¡tachán!, tendremos una curva que se alarga indefinidamente en el tiempo, prediciendo todo lo que va a pasar. Entonces, a subir el manuscrito a un repositorio público de preprints [artículos sin revisión externa] y, a veces, ni eso, hacer que nuestra universidad publique una nota de prensa con título ampuloso, y decirle al político de turno lo que debe hacer y lo que no. ¿Qué puede salir mal?
Pues todo. Si se busca un poco en la hemeroteca, se puede comprobar que estas predicciones fallan más que una escopeta de feria. Un ejemplo impactante es el del grupo MUNQU de la Universitat Politècnica de València, que estuvo publicando informes diarios con previsiones hasta el 22 de marzo. Ese día, predecían un pico de la epidemia en España para finales de mayo con 800.000 casos activos reportados. El pico se produjo el 18 de abril, cuando el número de casos activos fue menor de 120.000. Y estamos hablando de un grupo serio que dejó de publicar previsiones cuando se dieron cuenta de que podían hacer más daño que bien, por lo que hay que agradecer su honradez intelectual. Los grandes grupos internacionales tampoco pueden colgarse muchas medallas. Un análisis de The Economist compara las predicciones del número de muertes en Estados Unidos hechas por tres de los equipos más acertados. Las predicciones del 12 de abril a dos semanas vista tuvieron un error en promedio del 17%.
La primera excusa que ponen todos los autores de modelos es la calidad de los datos que usan para calibrar sus parámetros, que, efectivamente, tras casi tres meses de epidemia en España, siguen siendo un desastre y una vergüenza. Pero no, aunque tener buenos datos ciertamente ayudaría, ni así se iban a arreglar estas bolas de cristal. ¿Estamos diciendo que unos modelos probados y comprobados, como los SIR, no funcionan con la covid-19? Para nada. Estamos diciendo que un análisis superficial e ingenuo de estos modelos, limitados a curvas de predicciones, a adivinar fechas de picos o de fin de la epidemia, es engañoso e inútil. ¿Por qué? Esa es la cuestión. Las epidemias se caracterizan por dinámicas exponenciales (o casi), en las que hay fases de cambio rapidísimo. En este tipo de dinámicas, la capacidad de hacer predicciones está mermadísima, porque el más ligero error en el modelo (y es imposible hacer modelos sin errores) produce en pocos días un error gigantesco. Es un fenómeno con el que todos estamos familiarizados en un campo diferente: la meteorología. Hablamos del famoso “efecto mariposa” (ya se sabe, una mariposa bate sus alas en Madrid y se produce un tifón en Filipinas). Y la predicción del tiempo nos enseña el camino a seguir: predicciones probabilísticas, como esas a las que ya nos tiene acostumbrados el parte meteorológico cuando nos dice que este domingo habrá un 30% de probabilidad de lluvia. Información que no es certeza, pero que es extremadamente útil igualmente. ¿Y qué diferencia a la epidemiología de la meteorología? Ahora sí: los datos.
Para la previsión del tiempo contamos con redes extensas de observatorios, que recogen de forma sistemática multitud de variables y las comunican en tiempo real a los centros donde se calculan las previsiones. Con las epidemias, en España ni siquiera hemos sido capaces de establecer protocolos para que las 17 comunidades autónomas comuniquen sus datos de forma fiable y consistente (no hablemos ya del origen de esos datos en cada comunidad). Y con la posibilidad, muy real, de un segundo rebrote en cualquier momento, del que, por la impredecibilidad inherente que hemos descrito no sabemos, de ocurrir, cuándo será ni, una vez empezado, lo que durará, ni su intensidad, tenemos que ponernos las pilas en dos aspectos. El primero: ignorar a los chamanes de las curvas y entender que los profesionales de los modelos siempre nos van a presentar incertidumbres, probabilidades, barras de error; no intentarán dar la fecha del pico pero serán capaces de discernir el efecto de distintas actuaciones y ayudar de verdad a tomar decisiones. Todo esto, claro, si mejoramos en el segundo aspecto: regularizar ya protocolos eficientes para la recogida y publicación de los datos diarios de la epidemia. En lo peor de la crisis tal vez no fuese lo prioritario, pero ahora que hay un respiro, es inexcusable. Nos va la vida en ello.
Saúl Ares, Grupo Interdisciplinar de Sistemas Complejos (GISC) y Científico Titular del Centro Nacional de Biotecnología del CSIC (@omeuxeito)
Mario Castro, GISC y Profesor de la Universidad Pontificia de Comillas
José A. Cuesta, GISC y Catedrático de la Universidad Carlos III de Madrid
Susanna Manrubia, GISC e Investigadora Científica del Centro Nacional de Biotecnología del CSIC
- Economía mundial
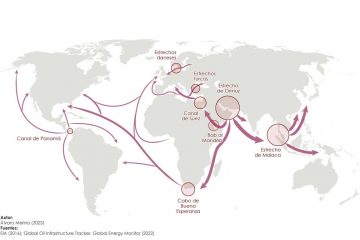
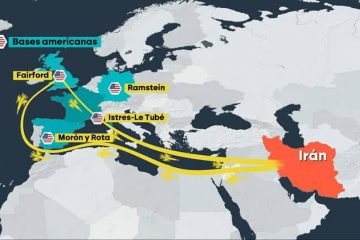
¿Por qué nos afecta la guerra en Irán?
- Guerra en Oriente Medio
Marco Rubio: “El estrecho de Ormuz estará abierto de una forma u otra”











![]()
El GRUPO EDITORIAL EXPRESS PRESS desea renovar su concepción y compromiso empresarial a través de una visión amplia e integradora, que más allá de la cuestión meramente económica, incorpore valores sociales, transparencia y ética profesional a fin de alcanzar la adecuada implementación de un modelo de negocio sustentable, acorde a los desafíos que nos plantea la revolución tecnológica.
